Quill One
Update: see the follow-up essay Quill Grid: The Starlink for AI becomes a network on how idle Quill devices can form an opt-in distributed AI grid.
1. Executive Summary
Quill One is a proposed 2034 sovereign AI compute module: a small, premium USB-C / Thunderbolt-class device that runs a frontier open AI model locally, privately, and offline. Plug it into a laptop, tablet, phone, kiosk, classroom terminal, robot, appliance, or public-service workstation, and you have a real local AI computer. The device supplies what the host lacks — local AI memory, a custom inference ASIC, a secure model store, signed updates, and sovereign local compute — while the host supplies the screen, keyboard, camera, battery, and radio it already has.
The original RefugAI concept from 2023 was a small, private, offline AI device for refugees: no wireless, USB-C charging and updates, voice/text interaction, solar charging, and a custom neural chip for a 1B-parameter chatbot. The original ambition was to manufacture and distribute 100 million devices by 2030, with an extreme $2–$10 manufacturing-cost target by 2029/2030. The 2034 version keeps the humanitarian core but updates the technical and market ambition. The goal is no longer a cheap 2023-level chatbot. The goal is frontier local AI in a compact module: a memory-compute product that can support a leading open 1–2T total-parameter-class sparse MoE model locally.
The core strategic shift:
Quill One is a fixed/reflashable-model AI module: 256GB active memory plus 500GB–1TB of field-reprogrammable read-mostly model memory.
Headline positioning
Quill One: The Starlink for AI.
Starlink made global connectivity feel like deployable infrastructure. Quill One should make sovereign AI compute feel the same way — distributed, resilient, useful at the edge, strategically important, and understandable.
The AI laptop problem
Most "AI laptops" are laptops with modest NPUs and limited on-device features, with meaningful intelligence still living in cloud assistants and vendor-controlled services. Quill One is a different category entirely: real AI in a sovereign module, where the intelligence runs on your device and stays there.
The OLPC pricing lesson
OLPC made the $100 laptop emotionally legible — a simple mission price helped people understand a new category of public-interest hardware. Quill One should use the same strategic clarity without making early manufacturing price the headline.
$100 is the mission price.
Recommended 2034 target spec
| Attribute | 2034 target |
|---|---|
| Product | Quill One sovereign AI module |
| Public framing | The Starlink for AI |
| Mission price target | $100 |
| Form factor | Flat USB-C / Thunderbolt-class AI module |
| Size target | 12–16 cm x 8–10 cm x 0.8–1.2 cm |
| Active memory | 256GB LPDRAM-class memory |
| Model store | 500GB–1TB field-reprogrammable read-mostly memory |
| Compute | Low-bit sparse-MoE inference ASIC |
| Model class | 1–2T total parameter sparse MoE, roughly 20–50B active params/token |
| Interface | USB-C physical connector, Thunderbolt 6-class 2034 assumption, backward path to TB5/USB4 |
| Power | 15–25W field target, 25–40W wall/dock target, 50–80W burst/docked |
| Cooling | Passive ribbed metal shell, optional fan/thermal dock |
| UI | Host-provided screen, mic, camera, keyboard, speaker |
| Connectivity | Wired only in base product |
| Deployment | Education, public-service, refugee support, robotics, developers, consumers |
2. Why Quill One Exists
AI is becoming a core layer of literacy, work, law, software, education, robotics, health, and government service. But the dominant delivery path is centralized cloud AI — expensive subscriptions, dependence on reliable internet and power grids, vendor control over access, political and export-control risk, privacy concerns, and fragile service continuity for displaced, remote, or low-income populations. The people who most need AI assistance often have the weakest access to it. That means refugees and forcibly displaced people, low-income students, rural learners, schools with weak connectivity, public libraries, clinics and field hospitals, legal-aid centers, disaster-response teams, small businesses, workers outside wealthy urban cloud markets, and robots that need low-latency local intelligence.
AI laptops and AI PCs are an important step, but the category is currently underpowered relative to the name. Many products are "AI-enabled" rather than true local AI computers — they provide acceleration for narrow features while the strongest assistant experience remains remote. Quill One creates a clearer category: a dedicated local AI compute module that upgrades ordinary host devices into sovereign AI workstations.
Software alone cannot solve this. A cloud assistant still requires cloud access. A small local NPU still cannot store or run a frontier model. A smartphone may be lost, censored, disconnected, or too weak. A laptop may not have enough memory. Quill One is a dedicated memory-compute object that makes local AI portable and institutionally deployable.
3. What Changed from the 2023 RefugAI Plan
The 2023 RefugAI memo proposed a small private offline AI device for refugees with a black-and-white text screen, microphone and voice input, rear camera for OCR, no wireless, no internet, USB-C charging and updates, solar charging, a custom neural chip for roughly a 1B-parameter chatbot, 100 million units by 2030, and a target manufacturing cost as low as $2–$10 by 2029/2030. The rationale was strong: refugees need translation, bureaucracy navigation, legal self-advocacy, education, job training, privacy, reliability, and independence from cloud AI subscriptions or internet access.
The updated plan keeps the original privacy and offline-compute logic but expands the product into a general sovereign AI platform.
| Dimension | 2023 RefugAI | 2034 Quill One |
|---|---|---|
| Primary use case | Refugee assistance | Education, refugee support, public services, robotics, consumers, developers |
| Target capability | 2023-level chatbot | Frontier local AI assistant / agent platform |
| Model scale | 100M–1B parameters | 1–2T total parameters, sparse MoE |
| Memory architecture | Small embedded memory | 256GB active memory + 500GB–1TB reflashable model store |
| Device form | Handheld with screen/mic/camera | Host-connected AI module |
| Interface | USB-C charging/data | USB-C / Thunderbolt-class host interface |
| Price dream | $2–$10 | $100 mission target, with first scaled production expected above the mission target before cost-down |
| Deployment date | 2030 | 2030 dev/test orders, 2033 first batches, 2034 scale |
| Industrial problem | Cheap AI chip | Memory capacity, model-store architecture, and sovereign manufacturing |
The updated strategic line: the 2023 idea was a humanitarian AI device. Quill One is a sovereign AI compute platform with humanitarian deployment as one of its first major missions.
4. Positioning: The Starlink for AI
Starlink is easy to understand: distributed hardware, useful in remote places, strategically important, infrastructure-like, and directly useful to people who cannot rely on conventional networks. Quill One can occupy a similar mental category for AI — distributed rather than centralized, locally useful rather than subscription-gated, resilient in weak-connectivity environments, strategically valuable to governments, personally valuable to consumers, and mission-critical for schools, libraries, clinics, and crisis zones.
| Message | Use |
|---|---|
| The Starlink for AI | Consumer, media, government, investor, and policy shorthand |
| Real AI in a sovereign module | Product definition |
| Citizen AI, not only data-center AI | Public-good framing |
| Local frontier AI for every school, clinic, robot, and community | Institutional framing |
$100 mission target.
That line is more powerful than a technical slogan because it explains the cost ambition in historical context. The public remembers that OLPC made the idea of mass educational hardware legible. Quill One should do the same for local AI compute.
5. Product Definition
Quill One should be the public product name. It is elegant, memorable, associated with writing and intelligence, compatible with the ribbed thermal design, friendly enough for schools and homes, and serious enough for governments. The platform can remain RefugAI or broaden to RefugAI Sovereign Compute. Recommended structure: RefugAI as the company/mission, RefugAI Sovereign Compute as the platform, Quill One as the product, Quill One Founder Kit as the 2030 preview hardware, and Quill One as the 2034 mass hardware.
Quill One is a compact wired AI module with a custom inference ASIC, 256GB active memory, 500GB–1TB field-reprogrammable model memory, minimal firmware, signed updates, Thunderbolt-class USB-C host connection, a passive cooling shell, and an optional dock for higher sustained performance. The host device provides the screen, keyboard, microphone, camera, speaker, network connection when desired, user files, robot I/O, and power or charging. That split is the key to the $100 mission target. Quill One is the AI memory-compute core that makes existing devices much smarter.
6. Markets and Use Cases
Refugee support remains a major humanitarian use case, but the product should be framed more broadly. The same hardware can serve multiple mission and commercial markets.
6.1 Education
Quill One can make AI tutoring local, private, and affordable for schools, public libraries, rural classrooms, homeschoolers, language learning, vocational training, coding education, and offline curriculum support. A school can attach Quill One to shared terminals and provide strong local AI without a cloud subscription for every student.
6.2 Refugees and displaced people
The original RefugAI use case remains one of the clearest humanitarian missions: translation, voice assistance through the host, bureaucracy navigation, legal self-advocacy support, local rights and services lookup, education and job training, cultural integration, private journaling and planning, and offline help when internet is unreliable or unsafe. The target should be 100 million public-good deployments, with refugees and displaced people as a priority beneficiary group. That avoids making refugees the only market while preserving the humanitarian center.
6.3 Public-sector and citizen services
Governments can deploy Quill One through schools, libraries, local-service offices, immigration and asylum offices, workforce-training centers, disaster response hubs, public health clinics, and national AI-sovereignty programs. The political message is strong: sovereign AI compute for citizens, not only for hyperscalers.
6.4 Robotics and embodied intelligence
Robots need low latency, local decision-making, privacy, resilience when connectivity drops, physical control loops, and cheap modular compute. Quill One can serve as a robot brain, a robot-limb module, a factory tool controller, an embodied agent runtime, or a field robot cognition module.
6.5 Consumers and developers
Consumers want a private AI assistant with no cloud subscription requirement, strong privacy, offline creative workflows, local document intelligence, and an upgrade path for existing laptops. Developers want a local model runtime, open SDK, robotics SDK, Englishscript / ClaudeVM-style app creation, signed workflow packs, and local agent tools.
6.6 Clinics, legal aid, and disaster response
Quill One can support institutional service points where connectivity or privacy is a problem: field hospitals, medical triage support, legal aid centers, refugee intake centers, disaster-response command posts, and local language translation in crisis zones.
7. 2034 Technical Architecture
The plan uses one flagship hardware product with multiple software modes — education mode, refugee support mode, legal/bureaucracy mode, coding/developer mode, local office mode, robot brain mode, robot limb mode, clinic/triage mode, low-power field mode, and docked turbo mode. One product keeps manufacturing, procurement, support, and messaging focused.
| Subsystem | Target spec |
|---|---|
| Form | Flat USB-C / Thunderbolt-class AI module |
| Public name | Quill One |
| Host UI | Host-provided screen, mic, camera, keyboard, speaker |
| Connectivity | Wired USB-C / Thunderbolt-class; base product designed for local operation |
| Power | USB-C PD / Thunderbolt-class power path; external battery, solar pack, dock, host, or robot power |
| Active RAM | 256GB LPDRAM-class memory |
| Model store | 500GB–1TB field-reprogrammable read-mostly HBF/NAND-like memory |
| ASIC | Low-bit sparse-MoE inference ASIC |
| Local storage | Additional NAND for documents, logs, local packs, deltas, adapter data, and update staging |
| Security | Secure boot, signed model updates, signed local packs, tamper evidence |
| Cooling | Passive ribbed metal shell, optional dock or thermal sleeve |
| Model | 1–2T total parameter open MoE-class model |
| Precision | 4-bit-class quality, mixed 2.5–4-bit / FP4 / FP8 physical representation |
| Active params | Roughly 20–50B active parameters/token target |
| Software | Local agent runtime, ClaudeVM/Englishscript-style app layer, translation, tutoring, legal workflows, robotics SDK |
The host device sends prompts, audio chunks, image frames, files, tool requests, or robot state over Thunderbolt-class USB-C. Quill One runs local inference using active RAM for the hot working set, the model store for base weights and cold experts, the ASIC for low-bit sparse inference, and a software memory manager for paged KV cache, hot/cold expert movement, local documents, and agent state. The host device then receives tokens, commands, tool calls, structured actions, embeddings, or robot-control outputs.
8. Thunderbolt 6-Class Host Interface
By 2034, the external interface should be specified as USB-C physical connector, Thunderbolt 6-class host link, with fallback compatibility to mature Thunderbolt 5 / USB4-class hosts where possible. The design should express the requirement as a performance class, not a dependency on a named standard not yet finalized. The current official reference is Thunderbolt 5 / USB4 v2-class performance: Thunderbolt 5 supports 80Gbps bidirectional bandwidth and up to 120Gbps with Bandwidth Boost, while USB4 v2 supports up to 80Gbps operation over certified cables. USB-C power delivery already reaches up to 240W in current Thunderbolt 5 ecosystems.
The external token stream is tiny relative to Thunderbolt-class bandwidth. Even multimodal inputs — text prompts, audio chunks, OCR text, image frames, local documents, robot state, tool calls — are manageable. The host link is for user I/O, file transfer, updates, and control; it is not the live model-weight bus. The model weights, hot experts, KV cache, routing, and scratch buffers need to live inside Quill One. A 49B-active MoE at 4-bit reads roughly 24.5GB of active weights per generated token before overhead. Internal memory architecture determines performance; the external cable does not.
Use this in public materials: Quill One uses the best mature USB-C high-speed standard available at launch, designed around Thunderbolt 6-class host bandwidth, high-power USB-C delivery, and backward compatibility where possible.
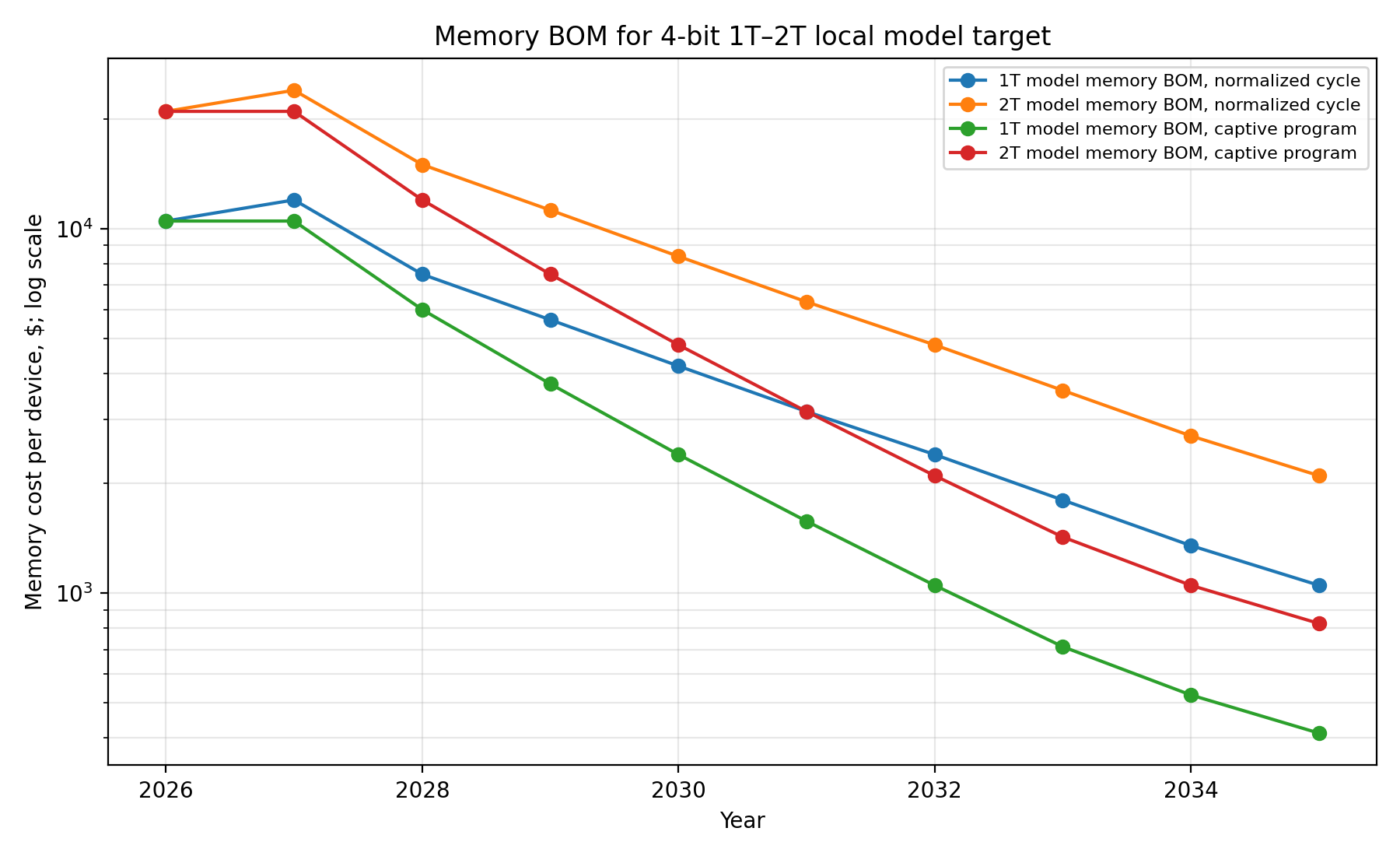
9. Model Target and Memory Math
The useful reference model shape is DeepSeek-V4-Pro-like: 1.6T total parameters, 49B activated parameters, 1M context, sparse MoE, mixed FP4 / FP8 representation, and compressed attention. The Quill One target is 1–2T total parameters, sparse MoE, 4-bit-class quality, 20–50B active parameters per token, compressed attention, and local agentic workflows.
| Model size | 4-bit raw storage | 3-bit raw storage | 2.5-bit raw storage | 2-bit raw storage |
|---|---|---|---|---|
| 1T params | 500GB | 375GB | 312GB | 250GB |
| 1.6T params | 800GB | 600GB | 500GB | 400GB |
| 2T params | 1TB | 750GB | 625GB | 500GB |
That is why the correct target is 500GB–1TB of model memory, not a small SSD and not a conventional laptop NPU. The 256GB active memory pool handles hot experts, KV cache, compressed/paged attention state, routing tables, scratch buffers, local tools, active documents, agent memory, safety and policy runtime, and host I/O buffers. The base weights live in field-reprogrammable read-mostly memory. That split is the core cost unlock.
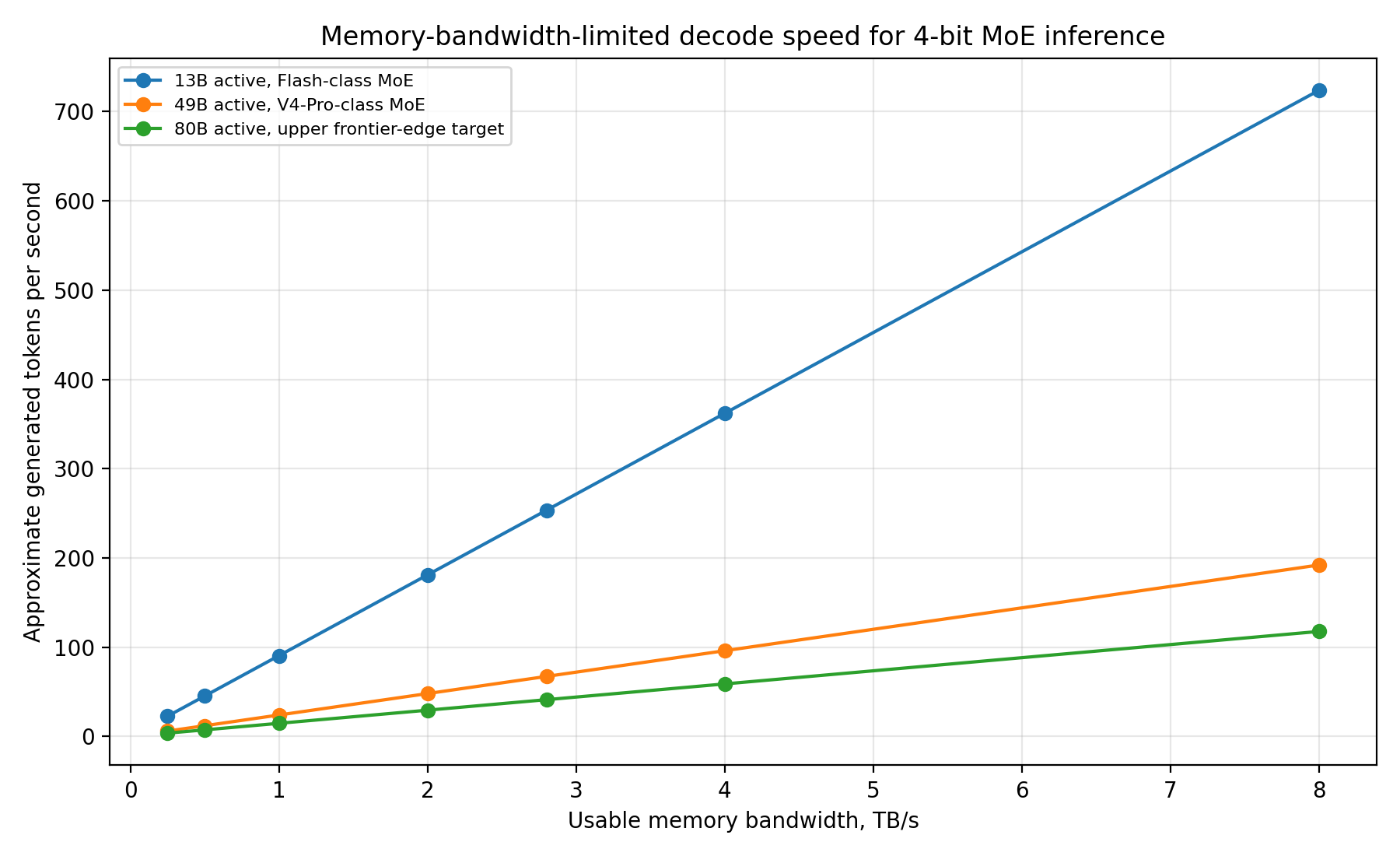
For a 49B-active MoE at 4-bit, active weights are roughly 24.5GB per generated token before overhead. With runtime overhead, a practical planning number is about 40GB per token. At 1TB/s usable internal bandwidth you get roughly 20–25 tokens/s; at 2TB/s roughly 40–50 tokens/s; at 4TB/s roughly 80–100 tokens/s. The exact result depends on routing, sparsity, cache reuse, speculative decoding, batching, quantization, and memory-controller design. The strategic point is stable: Quill One is a memory-bandwidth product as much as an AI-chip product.
10. TurboQuant, DeepSeek-Style Compression, and PagedAttention
Google's TurboQuant matters because it targets key-value cache and vector memory, reducing KV-cache and vector-search memory pressure while preserving quality in tested settings. This helps Quill One by reducing active RAM overhead for long-context agents, local RAG, semantic search, and memory-heavy workflows. TurboQuant does not erase the base-weight storage problem — a 1–2T model still needs hundreds of GB to 1TB of model storage — but it meaningfully shrinks the active working set.
DeepSeek-V4-Pro's published preview describes a large sparse MoE with 1M context and compressed attention approaches that reduce compute and KV-cache costs. Quill One should assume the leading open model by 2033/2034 will use similar or better techniques. The product should be model/runtime co-designed, not a generic accelerator running a generic transformer stack. PagedAttention treats KV cache like virtual memory; the broader lesson for Quill One is that the runtime should manage AI state like an operating system — hot experts, cold experts, model pages, active context, old context, local documents, embeddings, agent traces, cache compression.
The architecture assumes all three layers together:
| Layer | Function |
|---|---|
| Model architecture | Sparse MoE and compressed attention reduce active compute/cache |
| Quantization | TurboQuant-style KV/vector compression reduces active memory pressure |
| Runtime | Paged memory management keeps hot state in RAM and cold state in model store/NAND |
Together, these make 256GB active memory + 500GB–1TB model store plausible for 2034.
11. Reflashable Read-Mostly Model Memory
The model should live in field-reprogrammable read-mostly model memory. This is not literal mask ROM — it is normally read during inference but can be rewritten through signed update workflows.
| Update type | Cadence | Size | Purpose |
|---|---|---|---|
| Full base-model reflash | Annual | 500GB–1TB | New leading open model / major architecture update |
| Partial base rebase | Quarterly | Tens to hundreds of GB | Better experts, languages, code, safety, reasoning |
| Knowledge/legal/curriculum/local packs | Monthly or as needed | MB–GB | Local law, school curricula, relief info, bureaucracy, health guidance |
| Emergency safety/security patch | As needed | MB–GB | Security fix, policy patch, safety update |
At 100M units, the data-movement numbers are large:
| Update cadence | Data movement for 1TB model store |
|---|---|
| Annual full reflash | 100EB/year |
| Quarterly full reflash | 400EB/year |
| Monthly full reflash | 1.2ZB/year |
Annual full refreshes are reasonable with depots, schools, service centers, and staged update caches. Quarterly refreshes are possible for selected deployments but should be structured as deltas where possible. Reflash timing over USB4/TB5 80Gbps is about 1.7 minutes theoretical minimum for 1TB, with realistic encrypted write/verify around 10–45 minutes. The product experience should emphasize transparent updates, secure provenance, and local service points rather than constant full model replacement.
12. Memory Technology Path
The 2034 active memory target is 256GB — the minimum credible capacity for frontier local inference while still preserving a possible early scaled production path. Micron's 256GB SOCAMM2 LPDRAM module is a useful current anchor because it shows the capacity class already exists, with Micron describing lower power and smaller footprint than comparable RDIMMs. Quill One would require a much more consumer-scaled, cost-optimized, and tightly integrated 2034 implementation, but the direction is visible.
High Bandwidth Flash and similar NAND-derived model-store technologies are the main path to the price target. The goal is a nonvolatile, reflashable memory layer optimized for reading frozen AI weights — higher capacity than HBM, lower cost than 1TB of active DRAM, lower standby power, sufficient read bandwidth for model streaming, and field-reprogrammable updates. SanDisk describes HBF as a NAND-based AI inference memory direction, with first-generation concepts around 512GB per stack and high read bandwidth. This is exactly the kind of technology Quill One should try to anchor-demand.
HBM is valuable for data centers and may be useful in devkits, docks, robot modules, or premium industrial configurations. For the early scaled production mass product, the base strategy should prioritize LPDRAM-class active memory plus reflashable high-bandwidth model storage.
| Memory tier | Role | Target |
|---|---|---|
| Active LPDRAM | Hot experts, KV cache, working set, scratch | ~256GB |
| Reflashable model store | Base weights, cold experts, model pages | 500GB–1TB |
| Local NAND | Documents, packs, logs, staged updates | tens of GB to several hundred GB |
| Host storage | User files, media, host apps | host-dependent |
13. Size, Power, Heat, and Thermal Design
A flat shape is best because it spreads heat over a larger surface area. The ideal geometry is a thin slab rather than a chunky box.
| Attribute | Target |
|---|---|
| Length | 12–16 cm |
| Width | 8–10 cm |
| Thickness | 8–12 mm |
| Stretch thinness | ~7 mm if package and thermal design permit |
| Lower-power special version | ~5 mm possible only with reduced sustained power or dock dependence |
| Weight | 150–350 g consumer target; heavier for rugged/docked versions |
A 0.5 cm body is attractive visually, but it constrains memory package height, board stack, structural stiffness, connector durability, vapor chamber area, thermal mass, and dust and shock tolerance. The recommended mainstream target is 0.8–1.2 cm — still thin and futuristic while being credible as a 20–35W compute object.
| Mode | Power target | Use |
|---|---|---|
| Sleep/off | ~0–1W | Nonvolatile model store preserves weights |
| Idle/attached | ~1–3W | Waiting, host attached |
| Light AI | ~5–12W | Translation, tutoring, short answers |
| Field sustained | 15–25W | Normal public-service / school / refugee support work |
| Wall/dock sustained | 25–40W | Longer coding, agent, robot, classroom use |
| Turbo burst | 50–80W | Short bursts with dock, external fan, or robot chassis |
The enclosure is a functional part of the compute system. The recommended design is a ribbed aluminum or magnesium shell with a smooth top for handling and branding, ribbed sides and underside for thermal surface area, an internal vapor chamber or graphite spreader, a high-conductivity package-to-case path, thermal sensors and power-aware scheduling, and performance modes matched to ambient temperature.
| Alternative | Fit | Rationale |
|---|---|---|
| Passive ribbed shell | Core product | Silent, rugged, low maintenance, low BOM |
| Optional fan dock | Excellent accessory | Raises sustained performance for schools, desks, kiosks, and labs |
| External airflow | Useful in field | Ordinary fans materially improve ribbed passive cooling |
| Robot chassis integration | Excellent for robotics | Robot body/limb can act as heat sink and power source |
| Conductive thermal sleeve | Good for devkits/industrial | Adds cooling without changing core module |
| Sealed liquid-cooled dock | Specialized | Interesting for labs/robots, but too complex for mass public deployment |
Quill One should remain compatible with external solar and battery power, but at 20–35W it is best used with external USB-C battery packs, foldable solar charging, school/kiosk power, robot power, or duty-cycled inference. A 100Wh external battery gives roughly 10 hours at 10W, 5 hours at 20W, 3.3 hours at 30W, and 2 hours at 50W.
14. Industrial Design Concepts
The design has to excite consumers while reassuring governments that this is real infrastructure. The best direction is premium, quiet, durable, and iconic — not toy-like.
Quill One should combine a clean front/top surface, visible ribbed thermal identity, no unnecessary ornament, one small status light, one primary USB-C / Thunderbolt-class port, premium materials, sober colorways for government and school deployment, and special editions for consumer campaigns.
Concept 1: Urchin

A smooth front face paired with a dense pin-fin thermal back. Highly recognizable and memorable. Iconic, preorder-friendly, and the cooling visibly communicates itself. The expressive surface may collect dust and requires careful manufacturability work.
Concept 2: Quill Spine

A central thermal spine with radiating ribs — the most dramatic 2034 cyber-future concept. Beautiful hero imagery, strong flagship identity, powerful technical storytelling. More stylized than the base institutional product; best as flagship or special edition design language.
Concept 3: Warm Rib

A softer, warmer premium slab with integrated side fins and copper/titanium accents. Friendly, consumer-desirable, good for education and public spaces. Less austere for government procurement, but excellent for consumer launch.
Concept 4: Frontier Slab / Quill One base direction

A minimalist silver/graphite slab with finely integrated side ribs. This should be the production base direction. Credible, manufacturable, clean, easy to procure, easy to clean, durable, and professional. It needs material detail and branding discipline to feel iconic, but that is a solved problem.
Optional thermal dock

A rugged dock or sleeve that improves sustained performance for desks, classrooms, kiosks, labs, and robots. It gives a clear turbo-mode story while preserving the core module. Best for devkits, institutions, and performance users rather than the base mass product.
The recommended production identity: Quill One base module with Frontier Slab geometry and Quill rib language. The recommended launch imagery: Quill Spine as the hero cyber-future visual direction. Special editions and partnerships can sit on top of the core design — including gaming or character partnerships — but the core product identity should remain owned by RefugAI.
15. Cost Target and BOM Strategy
The public pricing line should be simple and consistent: $100 mission target. That line is powerful because it is specific, memorable, and aligned with the public-interest hardware tradition behind the original RefugAI concept. It belongs on the cover, summary slides, and public campaign materials. In detailed financial planning, the first scaled production runs may be above the mission target before memory capacity, yield, packaging, and manufacturing partnerships improve. An internal $199 scenario can be used as a cost-down checkpoint, but it should not be the headline or the public identity of the product.
A conventional design with 1TB of active RAM would not plausibly approach the mission price by 2034. The cost path requires 256GB active memory rather than 1TB active memory, 500GB–1TB reflashable read-mostly model memory, a custom ASIC rather than a general GPU, no integrated screen/mic/camera/battery/wireless in the base product, one high-volume flagship hardware product, government/fab/memory partnerships, and a demand book large enough to justify reserved capacity.
| Component | Extreme 2034 target | More realistic optimistic 2034 |
|---|---|---|
| 256GB active LPDRAM-class memory | $35–$60 | $70–$120 |
| 500GB–1TB reflashable model store | $20–$50 | $50–$100 |
| ASIC / chiplets / package / model-memory controller | $25–$45 | $45–$80 |
| PCB, Thunderbolt-class I/O, power, secure element | $8–$18 | $15–$30 |
| Rugged no-screen thermal enclosure | $3–$8 | $8–$15 |
| Test, assembly, yield loss, logistics reserve | $20–$45 | $35–$70 |
| $100M NRE amortization | ~$1 at 100M units | ~$1–$5 depending on scope |
| Total | ~$106–$229 | ~$224–$425 |
$100 is the mission price and long-term scale target. The first scaled production runs may be above the mission target. $224–$425 is a more realistic optimistic BOM without major subsidy or memory breakthroughs. A government/fab subsidy or cross-subsidy will likely be required to approach the mission price for public-good units.
| Requirement | Target |
|---|---|
| Active memory | 256GB below roughly $0.25/GB in captive volume |
| Model store | 1TB read-mostly model memory near $50 or below |
| ASIC/package | Below roughly $50 |
| Non-compute BOM | Aggressively minimized through host-provided UI |
| SKU count | One flagship mass hardware product |
| Demand | 100M–1B committed units or equivalent capacity commitments |
| Manufacturing | Government-backed memory/fab partnerships |
| Software | Open model/runtime co-design to reduce memory pressure |
| Updates | Annual/quarterly reflash model, not continuous base-weight churn |
16. NRE and ASIC Strategy
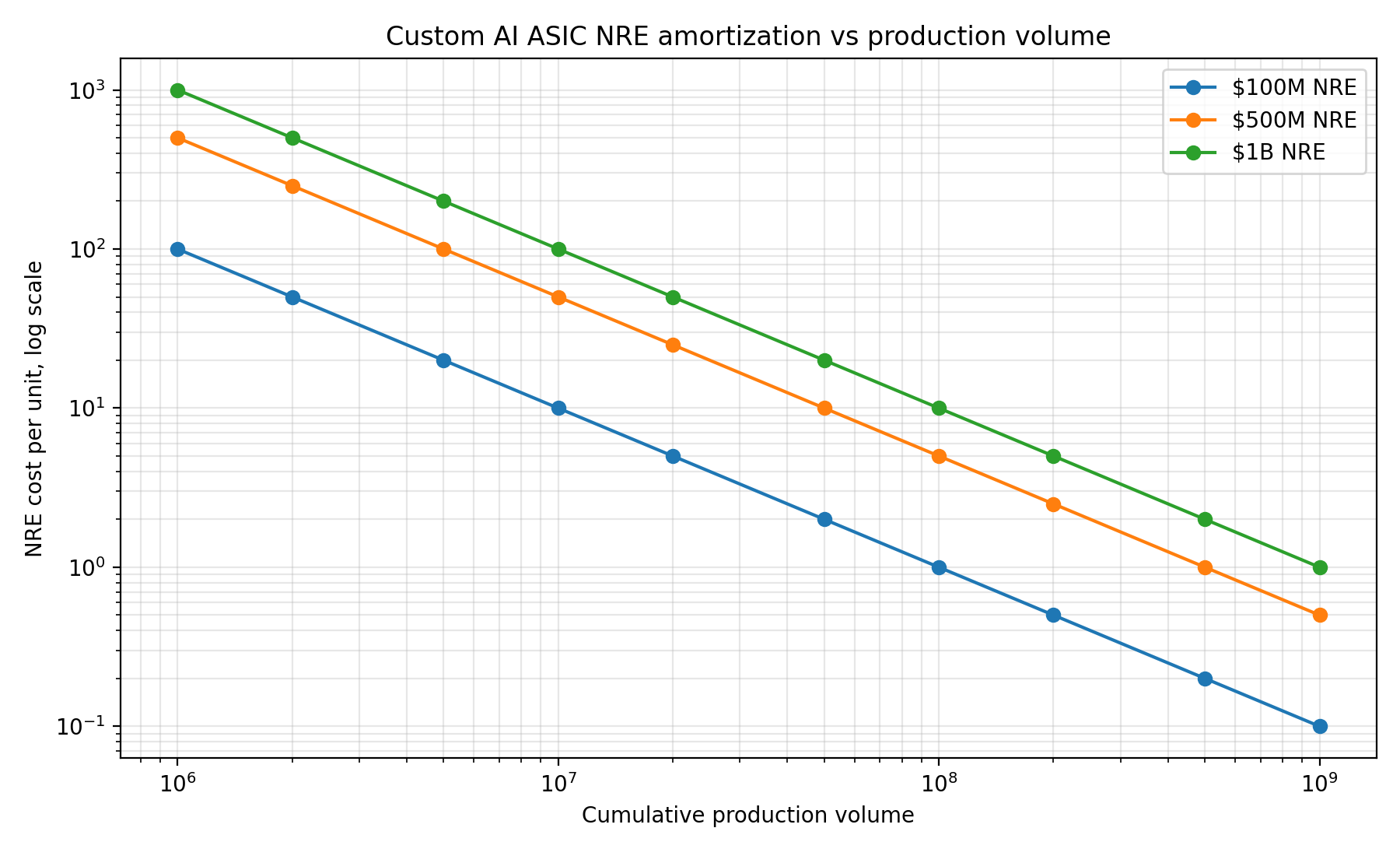
A $100M NRE target is plausible as an aspiration. The ASIC is specialized for a fixed model family, the design can focus on inference rather than general GPU workloads, open-source EDA and open chip approaches may contribute, universities and labs may donate architecture and compiler work, model labs may donate optimization knowledge, humanitarian branding can attract grants and volunteers, and the chip does not need to be a general-purpose data-center GPU. At 100M–1B units, NRE becomes small per unit anyway — $100M NRE amortizes to $1/unit at 100M and $0.10/unit at 1B. The hard problem is memory cost and memory capacity.
The ASIC should be optimized for sparse MoE inference, 2.5–4-bit weight formats, FP4 / FP8 mixed compute paths, compressed attention, model-store streaming, active memory efficiency, low-power decode, host-driven I/O, and secure update and provenance checking. The chip should be designed around a thermal envelope, not just peak speed.
17. Fab and Memory-Capacity Strategy
For 100M devices, the active DRAM requirement is enormous. At 256GB per unit, the total active memory needed is 25.6EB, requiring roughly 2.13M TB/month of output over a 12-month ramp — about 21 of what you might call 100k-TB/month fab-equivalents. A 1TB active-memory design would push into nearly 85 such equivalents over the same period, which is why the 256GB design matters so much industrially.
| Active memory per unit | Total active memory needed | Monthly output needed for 12-month ramp | 100k-TB/month fab-equivalents | Monthly output needed for 36-month ramp | 100k-TB/month fab-equivalents |
|---|---|---|---|---|---|
| 128GB | 12.8EB | 1.07M TB/mo | ~11 | 0.36M TB/mo | ~4 |
| 256GB | 25.6EB | 2.13M TB/mo | ~21 | 0.71M TB/mo | ~7 |
| 512GB | 51.2EB | 4.27M TB/mo | ~43 | 1.42M TB/mo | ~14 |
| 1TB | 102.4EB | 8.53M TB/mo | ~85 | 2.84M TB/mo | ~28 |
The model-store memory need is similarly enormous — 50EB at 500GB per unit, 100EB at 1TB — but NAND/HBF-like read-mostly model memory should be denser, cheaper, and lower standby power than active DRAM. Quill One is not simply a device project. It is an anchor-demand project for sovereign AI memory capacity. The project needs memory-company partnerships, government support, reserved capacity, packaging partners, and large preorder commitments.
18. Government and Fab-Partner Strategy
Governments want semiconductor jobs, AI sovereignty, education outcomes, resilient public services, refugee and migration support, disaster preparedness, local manufacturing, reduced dependency on foreign cloud providers, and technology that citizens can see and use. Quill One gives governments a concrete reason to support memory and packaging capacity: build memory capacity that becomes visible citizen AI infrastructure.
The potential structure: a government or regional authority subsidizes memory expansion or packaging capacity; RefugAI / Quill One commits to a device demand plan; local schools, libraries, clinics, refugee centers, and public offices receive deployment allocations; commercial, developer, and robotics sales cross-subsidize public-good units; local update depots provide signed model refreshes and jurisdiction-specific knowledge packs.
| Partner type | Role |
|---|---|
| Memory companies | LPDRAM, HBF/NAND model store, capacity planning |
| Foundries | ASIC fabrication |
| Packaging companies | model-store and memory-compute integration |
| Governments | subsidies, anchor procurement, deployment |
| Schools and ministries | education deployment |
| NGOs and UN-aligned agencies | refugee and humanitarian distribution |
| Robotics companies | high-volume commercial demand |
| Open model labs | model donation, compression, runtime co-design |
| Consumer electronics manufacturers | enclosure, assembly, QA, logistics |
A major fab costs about $10B+ and takes roughly 3–5 years. That means 2034 scale is plausible only if government and memory-partner work begins early.
| Year | Memory/fab objective |
|---|---|
| 2026 | Define memory architecture and partner requirements |
| 2027 | Begin memory-company and government MOUs |
| 2028 | Secure pilot capacity and packaging partners |
| 2029 | Demonstrate model-store prototypes and reflash process |
| 2030 | Use founder/dev campaign to prove demand |
| 2031 | Lock early capacity commitments |
| 2032 | Qualify supply chain and update depots |
| 2033 | First real batches |
| 2034 | Scale deployment |
19. Preorder and Campaign Strategy
The 2030 product should be a premium preview/dev/test system. Price: $9,000. Audience: developers, robotics labs, schools, philanthropists, governments, serious AI users, makers, and early believers. Purpose: prove demand, fund ASIC work, build software ecosystem, recruit memory partners, validate host integration. At 10,000 founder/dev orders that is $90M; at 100,000 it is $900M; at 1,000,000 it is $9B.
The Founder Kit includes early high-performance hardware, the local runtime, emulator and simulator access, robotics SDK, local agent SDK, model-store/reflash development tools, credit toward 2033/2034 Quill One, and a public-good sponsorship allocation.
| Buyer | Commitment type |
|---|---|
| Governments | 1M–50M school, citizen, public-service, refugee support units |
| Ministries of education | classroom and library deployments |
| NGOs | refugee-center and disaster-response deployments |
| Robotics companies | robot and limb AI modules |
| Developers | Founder Kit and first-batch devices |
| Consumers | buy one / sponsor one |
| Donors | sponsored public-good deployments |
| Fab partners | memory allocation tied to local deployment |
Buy one to own your AI. Sponsor one to give someone else a private teacher, translator, advocate, and toolmaker.
20. Decentralized Compute vs Data Centers
Quill One is not a replacement for all cloud AI. Data centers will remain essential for training, large-scale serving, scientific computing, and enterprise workloads. But cloud-only AI is brittle — it depends on grid capacity, data-center buildout, water and cooling infrastructure, permitting, local politics, cloud pricing, export controls, geopolitical stability, network access, and privacy trust. The IEA projects that global data-center electricity demand could roughly double to around 945TWh by 2030. U.S. state regulation is also shifting as local governments respond to energy and community impacts.
Hyperscale cloud is powerful but concentrated. Quill One is local, private, distributed, field-deployable, and citizen-owned. Space data centers may be interesting for some long-term infrastructure scenarios, but they add launch, repair, radiation, orbital security, latency, and capital complexity. A terrestrial sovereign AI device network can use consumer-electronics logistics, local hosts, local power, and public procurement.
Once millions of Quill One devices exist, their idle capacity does not have to sit unused. Quill Grid is the optional, opt-in network where Quill owners can share spare AI capacity, earn Quill Credits, donate AI hours to humanitarian and educational use, or pool capacity inside schools, cities, and governments. Quill One stays private by default; Quill Grid turns the install base into a people-owned distributed AI utility. See the full essay: Quill Grid — The Starlink for AI becomes a network.
21. Software: ClaudeVM / Englishscript-Style Local Computing
Quill One should not be sold as "just chat." It should be sold as a local software platform. The capabilities include natural-language apps, local agents, coding assistants, document workflows, translation, local OCR through host camera, legal/bureaucracy workflows, school tutoring, curriculum packs, robot-control policies, signed community workflow packs, local tool calls, private local memory, and offline-first operation. The user experience should feel like a private AI computer that turns any host device into a frontier local workstation.
A ClaudeVM / Englishscript-style layer lets users build and run software through natural language — "Make me a study plan for this exam," "Help me fill this immigration form," "Translate this letter and explain my options," "Write a robot inspection routine," "Build a local inventory app for this clinic," "Teach this concept in my language." The value is not only model intelligence. It is model intelligence embodied as local workflows.
22. Safety, Trust, and Public Deployment
Quill One should be designed around local-first operation, user control over exported data, signed model updates, secure boot, tamper-evident casing, transparent model provenance, open-source runtime where feasible, audit tools for institutions, local knowledge packs vetted by partners, and safe deployment modes for schools and clinics. Privacy is a core product feature, especially in refugee, school, clinic, and public-service settings — the base experience should not require sending personal conversations to a remote cloud assistant.
Institutional deployments should support jurisdiction-specific packs, school policy packs, legal disclaimers, medical and emergency disclaimers, age-appropriate education modes, update logs, and local administrative controls.
23. Risks and Constraints
| Risk | Mitigation |
|---|---|
| $100 mission target may be difficult by 2034 | Use subsidy/cross-subsidy, phased scale, and memory partnerships while keeping the public mission target simple |
| Memory supply may be constrained | Start memory partnerships early; reserve capacity; use HBF/NAND model store |
| 256GB active memory may be tight | Co-design model/runtime; use compressed attention, TurboQuant-style KV compression, paged memory |
| HBF may mature slower than expected | Maintain fallback paths: LPDRAM plus NAND paging, higher-cost early units, partner roadmap |
| Thermal performance may be challenging | Flat ribbed shell, power caps, optional dock, external airflow, robot chassis integration |
| Reflash logistics may be heavy | Annual full reflash, quarterly deltas, local caches, depot workflow |
| Fixed/reflashable model may age | Signed base refreshes, partial rebases, local packs, annual model upgrade plan |
| Governments may move slowly | 2030 founder/dev campaign proves demand before procurement cycles |
| Humanitarian procurement is complex | Work through schools, libraries, NGOs, local governments, and sponsor-one campaigns |
| Safety/legal liability | Vetted domain packs, disclaimers, audit tools, trusted partners |
A 1TB active-RAM handheld is a $1,000+ class device. A 256GB active-memory + 1TB reflashable-model-store Quill One creates a credible path toward the $100 mission target, but only with dedicated memory capacity, model/runtime co-design, and public-private subsidy.
24. Planning Curves
These curves are scenario tools, not certified forecasts. They explain why compute can improve quickly while memory capacity remains the industrial bottleneck.
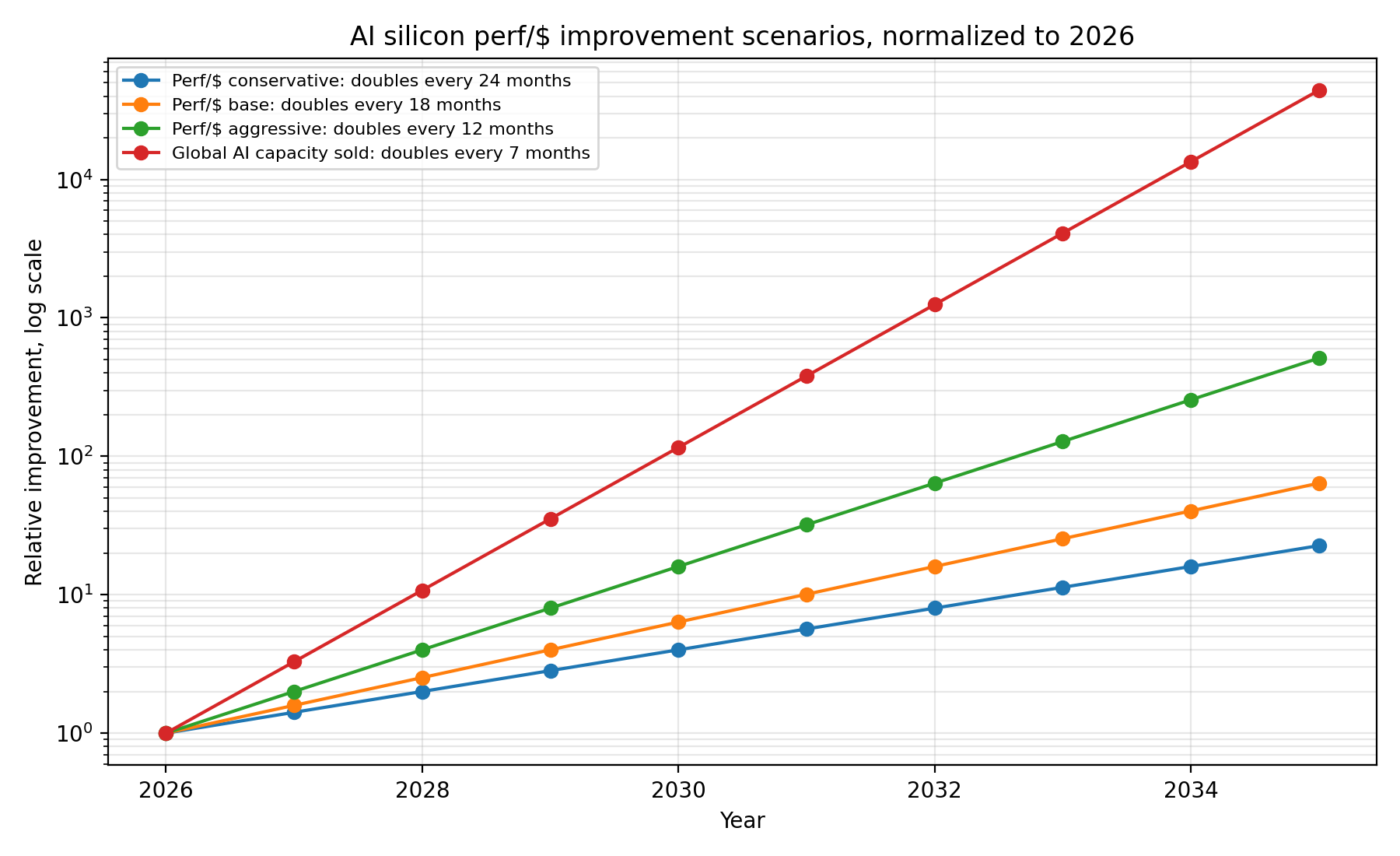
AI silicon performance per dollar
ASIC NRE amortization
Memory BOM for 1T–2T 4-bit target
Memory-bandwidth-limited token speed
25. One-Page Summary
Quill One 2034
- A sovereign local AI module for education, public services, refugee support, robotics, developers, and consumers.
- Public frame: The Starlink for AI.
- Price frame: $100 mission target.
- Hardware: one flagship device, no built-in screen, no built-in keyboard, no large built-in battery.
- Interface: USB-C physical connector with Thunderbolt 6-class 2034 host assumptions.
- Memory: 256GB active LPDRAM-class memory plus 500GB–1TB field-reprogrammable read-mostly model store.
- Model: 1–2T total parameter sparse MoE class, roughly 20–50B active parameters/token.
- Runtime: compressed attention, TurboQuant-style KV compression, paged memory management.
- Power: 15–25W field target, 25–40W dock/wall target, 50–80W burst.
- Cooling: flat ribbed thermal shell with optional dock and external-airflow compatibility.
- Timeline: 2030 founder/dev/test orders, 2033 first batches, 2034 scale manufacturing.
- Industrial strategy: government-backed memory/fab partnerships and 100M–1B demand commitments.
- Mission: bring real local AI to people and institutions outside the hyperscaler cloud.
26. Next Steps
- Finalize the name: Quill One.
- Prepare a 2-page teaser from this report.
- Create a 12-slide government/fab partner deck.
- Create a consumer preorder landing page.
- Build the 2030 Founder Kit specification.
- Recruit memory advisors: LPDRAM, HBF/NAND, packaging, wafer-capacity planning.
- Recruit model/runtime advisors: MoE, low-bit inference, KV compression, local agents.
- Build a simulator for model-store bandwidth, active RAM pressure, token/sec, power, and thermal performance.
- Prototype thermal slabs at 15W, 25W, 40W, and 80W burst.
- Develop education, refugee support, public-service, and robotics pilot workflows.
- Start government/fab conversations around sovereign compute for citizens.
- Draft sponsor-one / buy-one campaign mechanics.
27. Sources and Factual Anchors
The report uses the following factual anchors. They should be updated before external publication.
- Original RefugAI 2023 memo supplied by the user and hosted at https://jperla.com/blog/refugai. It established the first 100M refugee-device target, offline/no-wireless/USB-C design, solar option, custom AI chip direction, and $2–$10 cost dream.
- OLPC pricing history. The OLPC XO was famous as the "$100 laptop," while early real pricing was higher and the Give One Get One program charged for one received and one donated unit. Source: Wired and OLPC coverage.
- Thunderbolt 5 / USB4 current reference. Intel states Thunderbolt 5 supports 80Gbps bidirectional bandwidth and up to 120Gbps with Bandwidth Boost; USB-IF describes USB4 v2 up to 80Gbps operation. These are current anchors for a 2034 Thunderbolt 6-class assumption.
- DeepSeek-V4 model shape. DeepSeek's V4 preview lists V4-Pro as 1.6T total / 49B active parameters with 1M context, and V4-Flash as 284B total / 13B active.
- Google TurboQuant. Google Research describes TurboQuant as a compression method for KV cache and vector search, including strong memory reduction and attention-computation speed results in tested settings.
- PagedAttention / vLLM. The vLLM paper describes PagedAttention and reports major throughput gains through KV-cache memory management.
- SanDisk High Bandwidth Flash. SanDisk describes HBF as a NAND-derived high-bandwidth model-memory direction for AI inference, with 512GB first-generation stack concepts and high read bandwidth.
- Micron SOCAMM2. Micron's 256GB SOCAMM2 announcement is a current proof point for high-capacity, lower-power LPDRAM modules.
- Data-center power pressure. The IEA projects global data-center electricity consumption to roughly double to around 945TWh by 2030.
- Data-center regulatory pressure. State-level data-center bills have surged in 2026, with reporting and trackers citing more than 300 related bills across 30 states early in the year.
- Fab timing and cost. Intel describes a typical fab as costing about $10B and taking roughly 3–5 years.
- Memory scale. OpenAI's Stargate-related memory partnership targets up to 900,000 DRAM wafer starts per month, showing how strategic AI memory demand is becoming a sovereign-scale issue.
- Solar/battery trend. IRENA reports utility-scale solar PV around $0.043/kWh in 2024 and major battery cost declines since 2010.
Links
- Original RefugAI memo: https://jperla.com/blog/refugai and the uploaded user document.
- OLPC/Wired Give One Get One and pricing: https://www.wired.com/2007/09/give-1-get-1-pr
- Intel Thunderbolt 5 announcement: https://newsroom.intel.com/client-computing/intel-introduces-thunderbolt-5-standard
- Intel Thunderbolt technology overview: https://www.intel.com/content/www/us/en/architecture-and-technology/thunderbolt/overview.html
- USB4 overview: https://www.usb.org/usb4
- DeepSeek V4 preview: https://api-docs.deepseek.com/news/news260424
- Google TurboQuant: https://research.google/blog/turboquant-redefining-ai-efficiency-with-extreme-compression/
- vLLM / PagedAttention paper: https://arxiv.org/abs/2309.06180
- SanDisk HBF fact sheet: https://documents.sandisk.com/content/dam/asset-library/en_us//images/blog/2026/04/quill-one/public/sandisk/collateral/company/Sandisk-HBF-Fact-Sheet.pdf
- Micron 256GB SOCAMM2: https://investors.micron.com/news-releases/news-release-details/micron-sets-new-benchmark-worlds-first-high-capacity-256gb
- IEA Energy and AI: https://www.iea.org/reports/energy-and-ai/energy-demand-from-ai
- ArentFox Schiff data-center regulation tracker: https://www.afslaw.com/perspectives/alerts/state-regulation-data-centers-2026-shifting-landscape
- Reuters on data-center curbs: https://www.reuters.com/legal/government/dozen-us-states-weigh-data-center-curbs-maine-governor-vetoes-bill-2026-04-24/
- Intel fab explainer: https://newsroom.intel.com/tech101/how-a-semiconductor-factory-works
- OpenAI/Samsung/SK Stargate memory partnership: https://openai.com/index/samsung-and-sk-join-stargate/
- IRENA 2024 renewable costs summary: https://www.irena.org/-/media/Files/IRENA/Agency/Publication/2025/Jul/IRENA_TEC_RPGC_in_2024_Summary_2025.pdf
Enjoyed this essay?
Follow me for more insights on technology, startups, and the future.